Un routeur est un matériel ou un logiciel qui transmet des paquets en fonction des informations d’adresse IP dans les paquets qu’il reçoit. Il est plus courant d’acheter des paquets en fonction des informations d’adresse IP de destination , mais certains routeurs peuvent être configurés pour acheminer également les paquets en fonction des informations IP source.
Les routeurs effectuent la plupart de leur travail sur la couche de réseau (couche 3) du modèle OSI . Bien que les routeurs puissent fonctionner dans une seule interface (routeur à un bras), ils ont généralement au moins deux interfaces réseau, mais peuvent avoir beaucoup plus d’interfaces physiques et / ou logiques .
Tables de routage
Vous auriez tendance à penser que les routeurs sont des appareils réseau très complexes, mais en réalité, les routeurs de réseau setient en fonction de certaines règles simples chargées en mémoire . Ces règles dépendent de leurs tables de routage locales. Le routage commence lorsque les paquets entrent dans le routeur. Le routeur dépouille les informations de couche 2 des cadres qu’il reçoit.
Si le routeur est configuré pour rouler en fonction des informations IP de destination (qui est le formulaire de routage le plus courant), le routeur inspecte l’adresse IP de destination de chaque paquet, puis envoie le paquet au port correct. Le routeur utilise la table de routage pour prendre cette décision. Essentiellement, c’est le processus complet en un mot. La table de routage est la clé du processus de transfert des paquets vers leur destination appropriée.
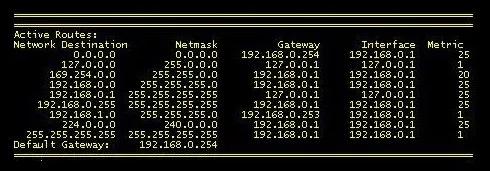
Chaque ligne de la table de routage définit un seul itinéraire . Chaque colonne identifie des critères spécifiques afin que le routeur puisse correspondre au meilleur itinéraire pour le paquet qu’il essaie de transmettre.
- Destination réseau: toutes les interfaces réseau, sous-réseaux locaux et sous-réseaux distants que le routeur connaît sera répertorié.
- Masque de réseau: les masques de sous-réseau sont utilisés en conjonction avec les informations IP pour déterminer l’ID réseau et l’ID hôte dans une adresse IP. Le routeur utilise ces informations pour déterminer s’il existe une correspondance entre le paquet qu’il inspecte et tout élément répertorié dans la table de routage. S’il y a une correspondance , la colonne d’interface dans la table de routage indique au routeur quelle interface pour envoyer le paquet.
- Route par défaut: la première entrée affichant la destination réseau de
0.0.0.0est considérée comme l’itinéraire par défaut du routeur. Si aucune autre entrée dans la table de routage ne peut être égalée, le routeur envoie le paquet à sa passerelle par défaut . L’itinéraire par défaut est très important car cela indique au routeur exactement quoi faire avec chaque paquet entrant à moins que le routeur ne puisse faire une correspondance avec une autre entrée dans la table de routage.
Les routeurs ne sont pas les seuls appareils qui utilisent des tables de routage. Tous les hôtes TCP / IP sur le réseau ont des tables de routage. Les ordinateurs avec un seul NIC ont des tables de routage très simples. Ils ont quelques entrées sur le sous-réseau auquel ils sont connectés et une entrée pour l’itinéraire par défaut. Cependant, certains ordinateurs peuvent avoir plus d’une connexion réseau . Par conséquent, tout comme les routeurs, les ordinateurs utilisent le même processus pour déterminer le port réseau à utiliser pour envoyer des paquets IP.
Pour les appareils qui ont plus d’un adaptateur réseau , ils sont appelés systèmes multi-hommés. Vous avez peut-être également remarqué que la table de routage a une colonne métrique. La métrique est une valeur relative qui définit le coût d’utilisation de cette voie .
Si un TCP / IP a plus d’un itinéraire disponible pour atteindre le nœud de destination, il utilisera l’itinéraire avec la métrique la plus basse . Si le nœud TCP / IP détermine que l’une de ses routes n’est pas disponible, elle ajustera la métrique ou supprimera l’itinéraire de sa table .
Routage statique et dynamique
Les tables de routage sont remplies à l’aide de deux méthodes . Soit les informations sont saisies manuellement (statiques) , soit apprendre (dynamique) sur les itinéraires provenant d’autres sources telles que les routeurs voisins. Bien que le routage statique fonctionne parfaitement bien, sur de grands réseaux, il peut être difficile de maintenir ces tables, surtout si la disposition du réseau change régulièrement.
Dans une topologie en maillage complète , les liens peuvent baisser, le changement de dispositifs de réseau et d’autres facteurs peuvent ajouter à la gestion accrue d’un routeur de réseau. Avec un routage dynamique , vous permettez aux routeurs de gérer leurs propres tables de routage.
Routage Internet
Les routeurs sur Internet public ne partagent pas les informations de routage avec des protocoles de routage tels que RIP ou OSPF . Ils utilisent le concept appelé système autonome (AS) . Les systèmes autonomes utilisent un numéro de système autonome ( ASN ) unique à l’échelle mondiale attribuée par l’IANA.
Tout comme vous attribueriez une adresse IP à l’interface d’un routeur, vous configureriez le routeur pour utiliser l’ASN attribué par l’IANA. Les systèmes autonomes communiquent entre eux à l’aide d’un protocole de passerelle extérieur (EGP).
Les réseaux au sein d’un AS communiquent avec des protocoles connus sous le nom de protocole de passerelle intérieur (IGP) . Pour l’Internet public, la communauté s’est installée sur un protocole de communication entre chacun, connu sous le nom de Border Gateway Protocol (BGP) .
Routage des vecteurs de distance
Les protocoles de routage des vecteurs de distance ont été les premiers à apparaître dans le monde de routage TCP / IP. Les protocoles de routage des vecteurs de distance sont généralement utilisés sur les routeurs LAN . La base de tous les protocoles de routage des vecteurs de distance est une forme de coût. Le coût d’un itinéraire est composé du nombre de houblon, qui est le nombre d’interfaces entre la source et le réseau cible.
Si vous aviez un routeur à un saut d’un réseau, le coût de cette route serait 1. RIP, ou protocole d’information de routage , est un exemple de protocole de routage de vecteur de distance. Bien que les protocoles de routage des vecteurs de distance soient faciles à mettre en œuvre et à gérer, ils ont leurs limites .
Par exemple, vous pouvez avoir plusieurs voies vers un réseau cible. Le chemin avec deux sauts peut être configuré avec des liens très rapides tandis que le chemin avec un houblon est un lien très lent. Pour cette raison, les mesures sont affectées aux itinéraires afin qu’elles puissent être calculées dans le cadre du coût total de l’itinéraire.
Les liens plus rapides se voient attribuer des mesures plus basses que les liens plus lents pour garantir que le routeur choisit le chemin le plus rapide vers le réseau de destination. Les protocoles de routage des vecteurs de distance calculent le coût total pour accéder à un réseau particulier et compare ce coût au coût total de tous les autres itinéraires pour accéder au même réseau. Le routeur choisit alors l’itinéraire avec le coût le plus bas . Les routeurs utilisant un protocole de routage de vecteur de distance échangent leurs tables de routage entre eux.
Routage d’état de liaison
En raison de certaines des limites du routage des vecteurs de distance , telles que la vitesse et les protocoles de routage plus optimaux plus optimaux ont été développés. Le protocole de routage dynamique d’état de liaison est une meilleure option pour les réseaux qui ont un grand nombre de routeurs qui échangent dynamiquement leurs tables de routage.
Le routage de l’état du lien envoie uniquement des informations de routage à mesure que le réseau change et envoie uniquement les modifications , plutôt que d’envoyer l’intégralité du tableau de routage à des intervalles spécifiés. Le chemin le plus court ouvert en premier (OSPF) est l’IGP le plus couramment utilisé. OSPF converge considérablement plus rapidement et est beaucoup plus efficace que RIP. Contrairement à RIP, OSPF est un protocole complexe pour les routeurs.


{kind=link}